海量数据计算应该如何选择数据库
本文共 522 字,大约阅读时间需要 1 分钟。
背景
随着大数据的应用越来越广泛,应用的行业也越来越低,我们每天都可以看到大数据的一些新奇的应用,从而帮助人们从中获取到真正有用的价值。在阿里云的云数据库RDS版中,提供了大数据计算服务(MaxCompute,原名ODPS),它是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。通过数据集成服务,可将 RDS 数据导入 MaxCompute,实现大规模的数据计算。下面以 MaxCompute 和 RDS 搭配为例介绍大数据应用计算方案。
前提
需开通 MaxCompute 服务,并完成项目设置。
需开通数据集成服务
操作步骤
1. 登录 ,选择目标实例。
2. 在 RDS 实例上增加数据集成的白名单。

3.登录 ,创建 MaxCompute 数据表。
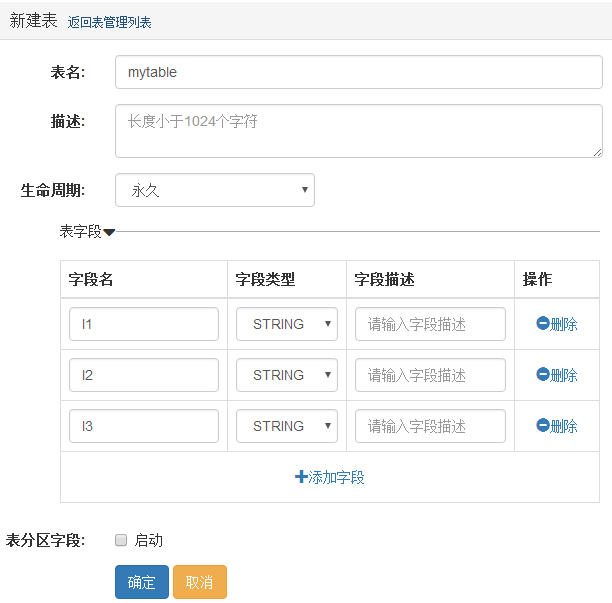
4. 登录 ,设置 RDS 源库和 MaxCompute 目标库信息。
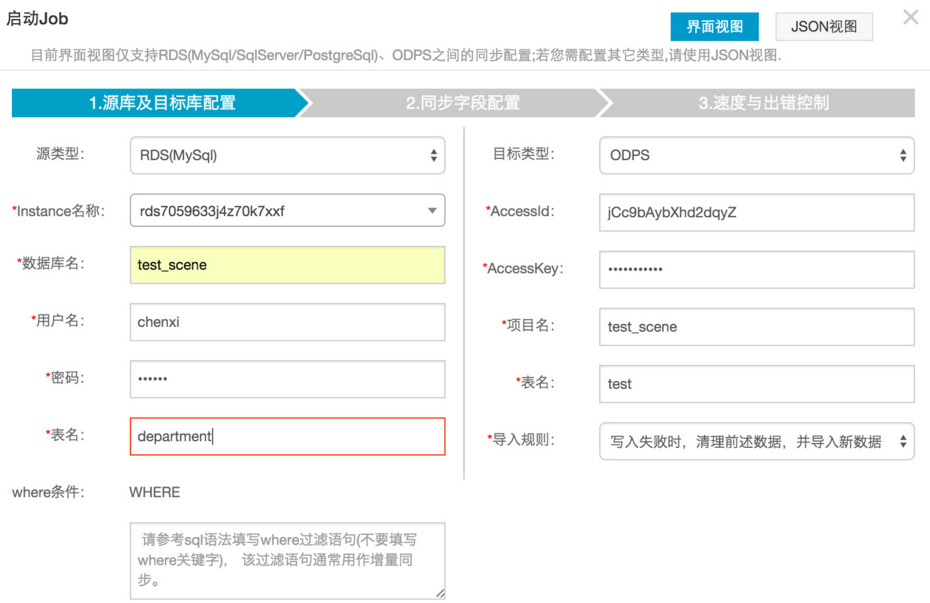
5 设置数据集成同步字段。
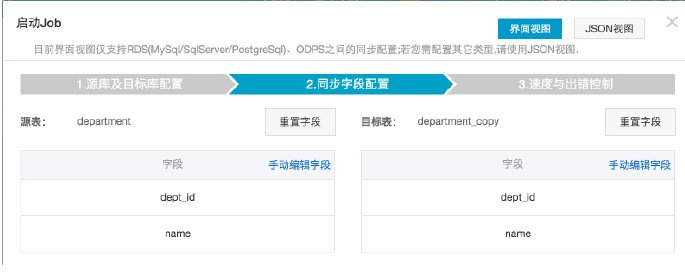
6.设置数据集成速度与出错控制。
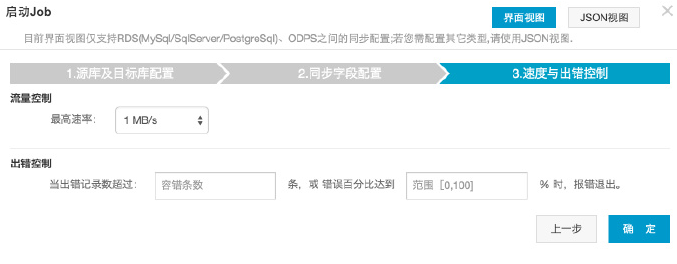
7. 完成设置后,将数据导入 MaxCompute。
8.登录 ,执行查询操作,如下图所示。

参考
转载地址:http://zjbva.baihongyu.com/
你可能感兴趣的文章
Vue.js 中v-for和v-if一起使用,来判断select中的option为选中项
查看>>
Java中AES加密解密以及签名校验
查看>>
定义内部类 继承 AsyncTask 来实现异步网络请求
查看>>
VC中怎么读取.txt文件
查看>>
如何清理mac系统垃圾
查看>>
企业中最佳虚拟机软件应用程序—Parallels Deskto
查看>>
Nginx配置文件详细说明
查看>>
怎么用Navicat Premium图标编辑器创建表
查看>>
Spring配置文件(2)配置方式
查看>>
MariaDB/Mysql 批量插入 批量更新
查看>>
ItelliJ IDEA开发工具使用—创建一个web项目
查看>>
solr-4.10.4部署到tomcat6
查看>>
切片键(Shard Keys)
查看>>
淘宝API-类目
查看>>
virtualbox 笔记
查看>>
Git 常用命令
查看>>
驰骋工作流引擎三种项目集成开发模式
查看>>
SUSE11修改主机名方法
查看>>
jdk6.0 + Tomcat6.0的简单jsp,Servlet,javabean的调试
查看>>
Android:apk签名
查看>>